Statistical performance#
Modern language models undergo at least two training stages: pretraining, and instruction training. When solving a classification task, it’s tempting to lean on instruction-style prompts in combination with text generation. This combination works incredibly well for multi-GPU, proprietary models. But what about smaller, open source ones? Perhaps there are smaller or undertrained models which are not good at generating a choice, but are good at estimating probabilities.
A handful of experiments suggests that CAPPr squeezes more out of smaller LLMs for text
classification tasks. In the OpenAI COPA demo, text
generation using OpenAI’s smaller model, text-curie-001, is less than 50% accurate.
CAPPr using the same model is 80% accurate. Similar but less wild results can be seen
in:
the 4-bit 4 GB Llama 2 COPA demo
the 4-bit 4 GB Llama 2 AG News demo
the 4 GB Mistral Craigslist Bargains demo
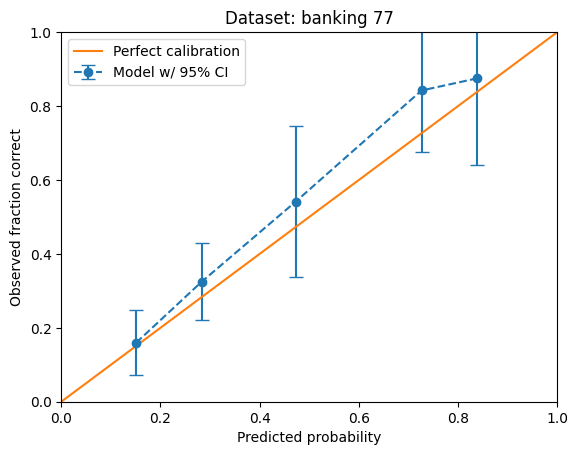
the 4 GB Mistral Banking 77 demo (with 77 multi-token choices)
the 4 GB Mistral Tweet Emotion demo (a multilabel problem).
I’ll study how replicable this result is across classification tasks, model sizes, and levels of quantization. I’ll also study explanations for these results. The working hypothesis is two-fold:
CAPPr-style prompt-completion formats can look more like pretraining data, which is typically where a lot of learning happens. This is demonstrated in the COPA demo
Despite strict instructions not to, models can generate “I don’t know”, or make a choice that’s difficult to map to the given list of choices. CAPPr instead has the model make its “best” guess among the given choices. This is demonstrated in the Banking 77 demo.
Calibration#
The calibration of CAPPr estimates has barely been studied. These estimates are slightly different than usual next-token log probability estimates because:
CAPPr hackily takes a mean over next-token log probabilities
CAPPr can incorporate a prior specific to your classification data.
The Banking 77 demo contains two low-resolution but interesting calibration curves. Here’s the nice-looking curve: